
ChatGPTより小規模のLLMモデルで90%の性能がうたい文句のFastChat(Vicuna)をより低価格なGPUで動作させる方法を考えてみた。
FastChatはオープンソースで公開されていて、自前のローカルな環境でも動かすことができるほどコンパクトなLLMだ。
オンプレミスで試験的に評価、運用することも可能。
それでも、vicuna-13b(130億パラメータ)モデルをフルスペックの16bit精度でinferrence(会話)するには
Nvidia A100 40/80GB クラスのGPUカードが標準的には必要だ。下手な車が買えそうな値段だが。
これを手持ちのRTX3090(24GB) + GTX1080Ti(11GB)でも動かせるようにした。
これでぐっとGPUの敷居が低くなって、だれでも簡単に自前で使えるモデルになりそうだ。
vicuna-7bとvicuna-13bではかなり性能に差がある、vicuna-13bを精度を落として8bitで使うと、微妙だが、無視できない差が出る。
せっかくのLLM(大規模言語モデル)なので、やはりvicunna-13bをフルスペックの16bit精度で動かしたい。
vicuna-13bをフルスペックで動作させるには26GB以上のGPU VRAMが必要となる。
RTX3090(24GB) + GTX1080Ti(11GB)の2枚のボードで合計35GB VRAMなので余裕で動作しそうだが
今までFastChatでは動作させることができなかったが、FastChatのGitHubに私の修正コードをPR(Pull Request)したら承認され、
本体(main)にマージされたので、現在のFastChatの最新版では動作するようになっている。
これで、
RTX3090/4090(24GB) + RTX2060/3060/4070(12GB) クラスのボード構成でも動く。
うまくいけば24GB + 8GB VRAMや16GB+12GB VRAMの構成でも動くかも知れない。
今までは、RTX3090/4090クラスのボードが2枚必要だったのだが、これで、だいぶボードのコストを抑えることができそう。
なぜ動かせるようになったかというと、HuggingFaceのTransformerでLLMを複数のGPUで効率よく動かすためのドキュメントを読むとわかるが、"device_map"と"max_memory"の重要なパラメータの使い方が良く分かってないと、いくら頑張っても、GPUが派手にmemoryエラーを吐き出すコードを書くことになる。
しっかりやって頂戴。オプンソースの長所と欠点はウラハラだ。
複数のGPUの構成によってはうまく動かない場合があるかもしれないが、その場合は"max_memory"を手動で微調整するといいかもしれない。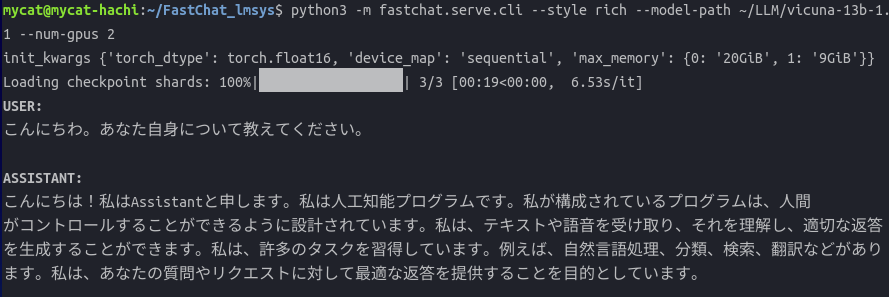
実際に動かしてみると、なかなかRichな答えが返ってくる。
このプロジェクトのGitHubを眺めていたら、いつの間にか私のハンドル名(ycat3)がContributors(開発貢献者)リストに載っていた。
まあ嬉しくはあるが、つらつらリストを見てみると、バークレイやスタンフォード等の大学院生が主体で開発しているようだ。
名前から察するに、ほどんどが中国系みたい。日本は影が薄いな。
ちなみに、画像のカッコいいミニスカ・ポリスのお姉さんは画像生成AIに作ってもらいました。
ついでに三流小説家の悩みを聞いてもらいました。
Llama2/Vicuna-7bをNvidia専用GPUボードがなくても動作する方法がある。
AMD Ryzen 5 5600G APU(CPU+GPU)等を利用して16GB VRAM搭載のGPUとして使うことができる。
コメント powered by CComment