
Meta/Llama 2ベースのFastChat/Vicuna v1.5をローカルPCで試してみた。
とうとう、Vicuna のllama2バージョンが公開された。
従来のVicuna v1.3はMeta/Llamaを使用しているので、商用利用が制限されていたが、
Vicuna v1.5は商用利用も可能で、130億パラメータの13B-16Kトークン対応版もある。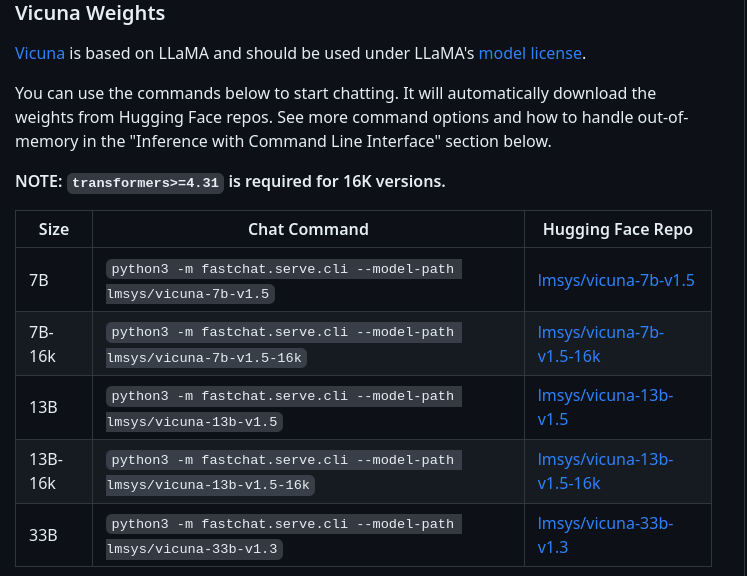
vicuna-13b-v1.5をローカルPCで実際に動かした。
GPUはRTX3090+GTX1080tiの2枚の少し変則的な組み合わせでも動く。
動作に必要なGPUメモリの合計は26GB以上になる。
vicuna-7b-v1.5だと、専用グラフィックスボードがなくても、Ryzen 5 5600Gでも動作するのを確認した。
Ubuntu22.04の環境で動かした。
名前はRyokoさんなんだ!
AIの危険性について尋ねてみると
まあまあ、ちゃんと答えてくれる。
地元、横浜は知ってるかな。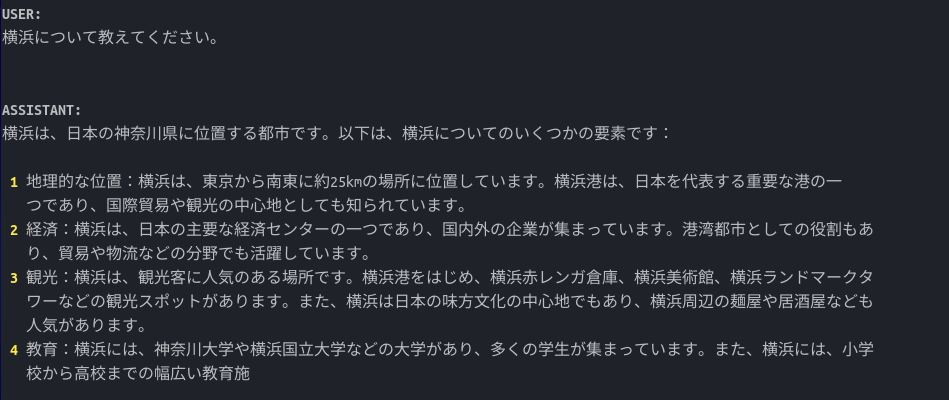
多言語対応のLLMで、日本語にもかなりのレベルで対応してる。
llamaベースでこのレベルまで出来てるLLMはほとんどないので、Vicuna v1.5を使って本格的な商用アプリが開発できるかもしれない。
興味のあるかたは問い合わせをしてみてください。
コメント powered by CComment