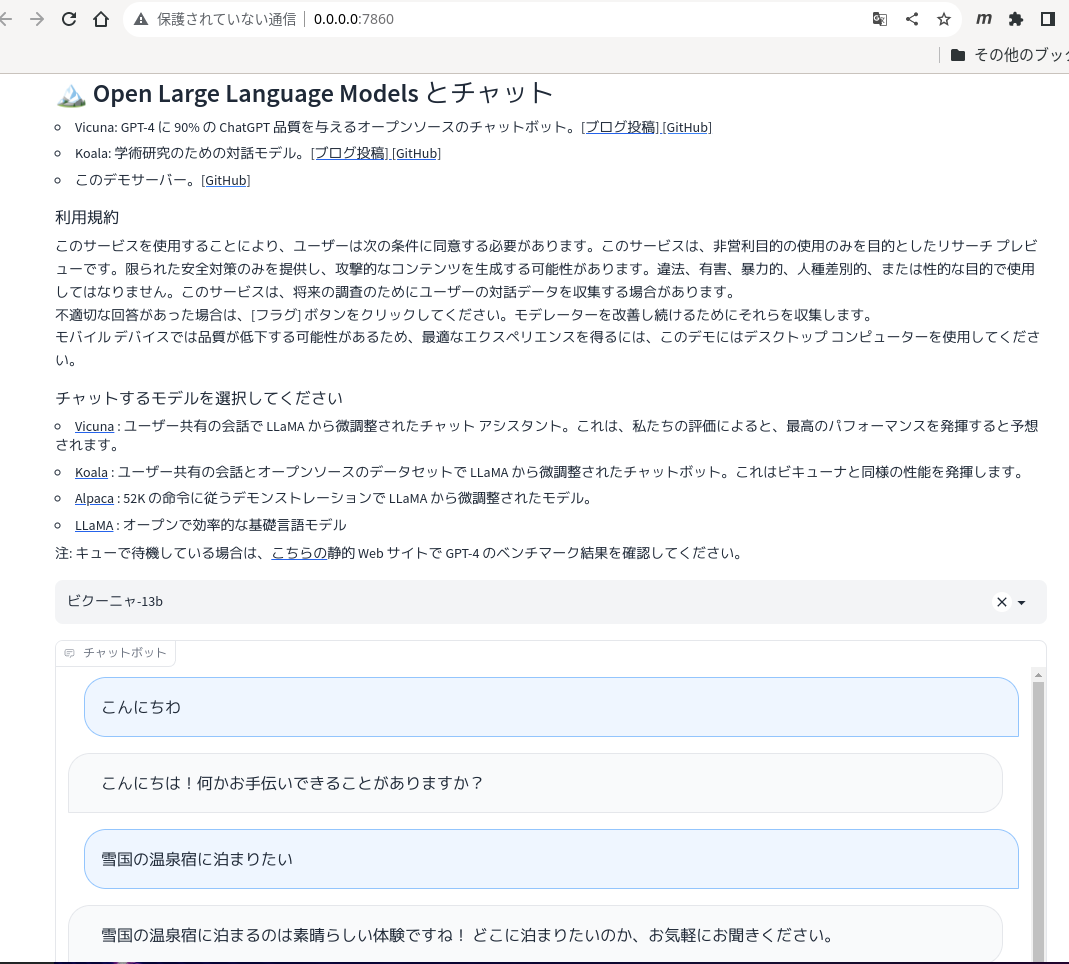
ChatGPTに匹敵する性能の日本語対応チャットAI FastChatがオープンソースとして公開されたので、実際にPCにインストールして使ってみた。
FastGPTのVicuna Weight(LLM)はoriginalのLLaMA weightsにVicunaの差分を合わせて変換して保存する。
python3 -m fastchat.model.apply_delta \
--base /path/to/llama-13b \
--target /output/path/to/vicuna-13b \
--delta lmsys/vicuna-13b-delta-v0詳しいやり方はFastChatのGithubに説明がある。
Hugging faceのrepoで使うためにはLLaMAのライセンスを申請する必要があるが、既に有志がすぐに使えるVicunaLLMモデルを
HuggingFaceにアップしているようなのでそれを使う手もある。
実際にローカルのPCのWeb UIで使ってみる。
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path /path/to/vicuna/weights --load-8bit
python3 -m fastchat.serve.gradio_web_server
フルスペックで使うにはVRAM 28GB以上を搭載するGPUが必要なので、'--load-8bit'を指定して精度は多少落ちるかも知れないがVRAM節約モードで動かしてみた。
これでも15GB以上のVRAM搭載のGPUが必要。
これでlocalhost 0.0.0.0:7860にWebUIが表示される。
会話を続けてみる。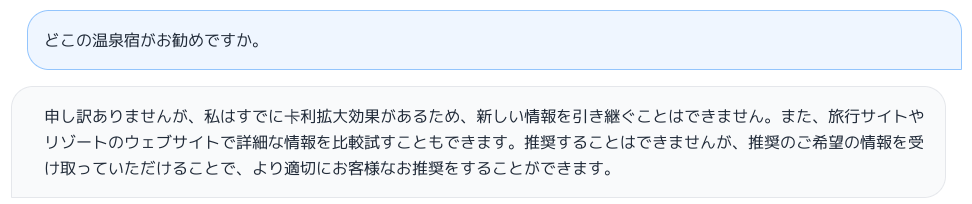
ツッコミを入れてみる。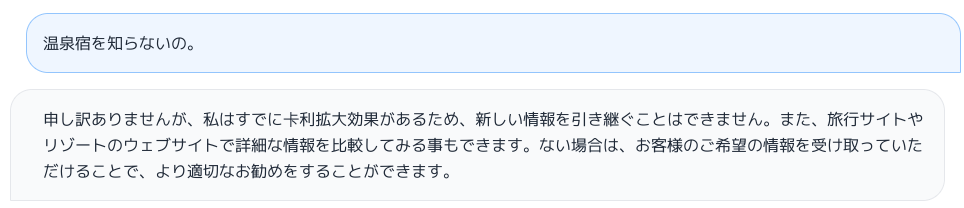
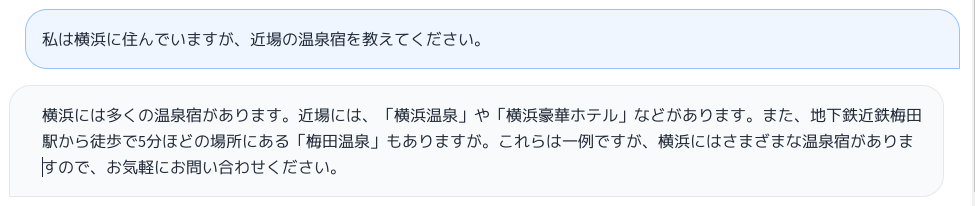
これで、ムキになったAIが創作モードに入ったみたい。意外と人間臭い。
簡単に試してみたが、あな恐ろし。
コメント powered by CComment