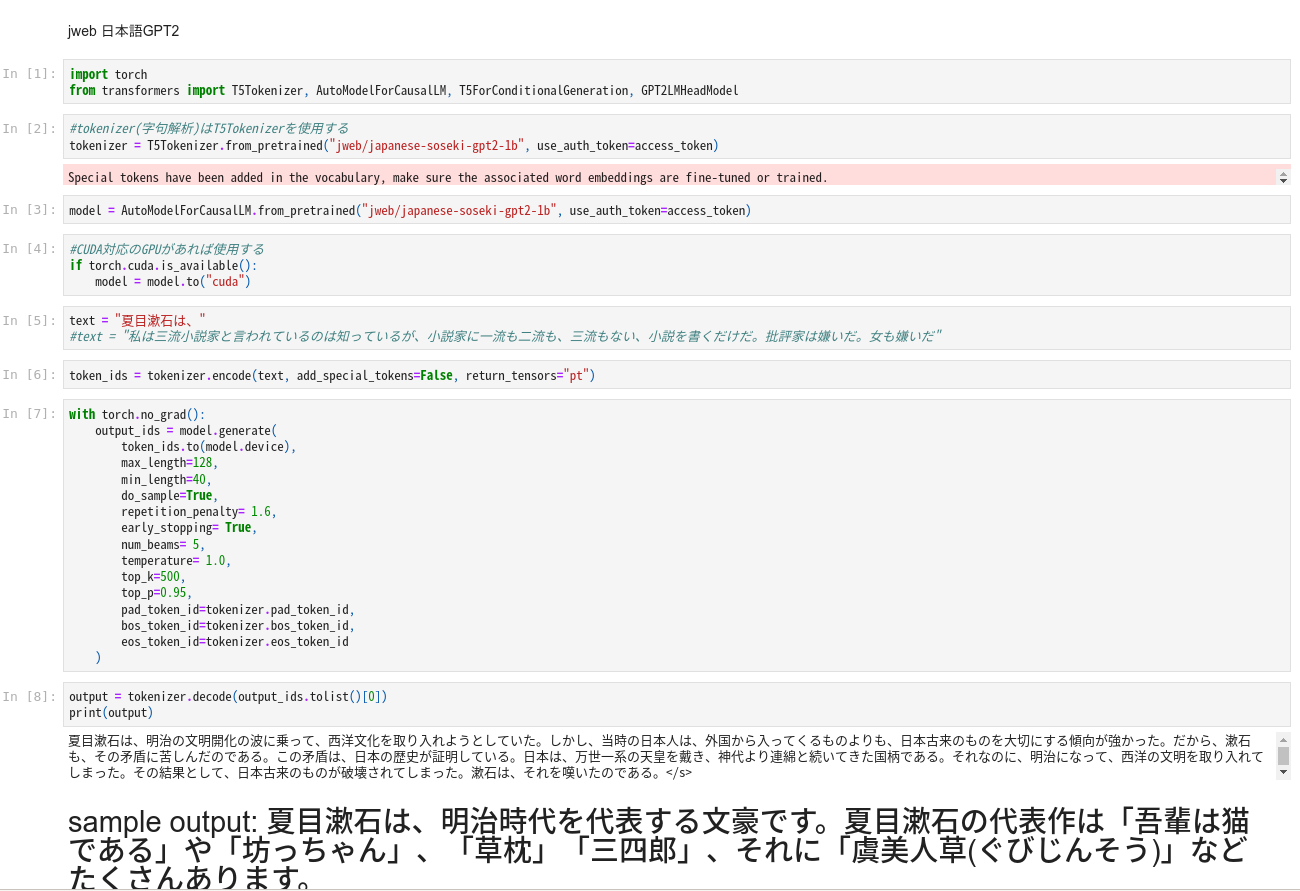
日本語で事前学習して、ファインチューニングしたGPT2の威力を、手軽にJupyter Notebookで試せるようにした。
以下のコードをNotebookにコピペして実行すると入力した導入フレーズを元に自動的に文章を作成します。
以下の例の導入フレーズは、
"夏目漱石は、"
です。
青空文庫の夏目漱石作品集で特別にファインチューニングしたので、漱石好きにはたまらない文章が生成されるかも知れません。
大規模なGPTモデルなので、最初のモデルロードにかなり時間がかかります。
このJupyter Notebook用のファイルはGithubに上げといたのでここからダウンロードできます。
jweb_gpt2.ipynb
-----------------------------------------------------------------------------------------------------------------------------
jweb 日本語GPT2
In [1]:
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM, T5ForConditionalGeneration, GPT2LMHeadModel
In [2]:
#tokenizer(字句解析)はT5Tokenizerを使用する
tokenizer = T5Tokenizer.from_pretrained("jweb/japanese-soseki-gpt2-1b", use_auth_token=access_token)
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
In [3]:
model = AutoModelForCausalLM.from_pretrained("jweb/japanese-soseki-gpt2-1b", use_auth_token=access_token)
In [4]:
#CUDA対応のGPUがあれば使用する
if torch.cuda.is_available():
model = model.to("cuda")
In [5]:
text = "夏目漱石は、"
#text = "私は三流小説家と言われているのは知っているが、小説家に一流も二流も、三流もない、小説を書くだけだ。批評家は嫌いだ。女も嫌いだ"
In [6]:
token_ids = tokenizer.encode(text, add_special_tokens=False, return_tensors="pt")
In [7]:
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_length=128,
min_length=40,
do_sample=True,
repetition_penalty= 1.6,
early_stopping= True,
num_beams= 5,
temperature= 1.0,
top_k=500,
top_p=0.95,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
In [8]:
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
夏目漱石は、明治の文明開化の波に乗って、西洋文化を取り入れようとしていた。しかし、当時の日本人は、外国から入ってくるものよりも、日本古来のものを大切にする傾向が強かった。だから、漱石も、その矛盾に苦しんだのである。この矛盾は、日本の歴史が証明している。日本は、万世一系の天皇を戴き、神代より連綿と続いてきた国柄である。それなのに、明治になって、西洋の文明を取り入れてしまった。その結果として、日本古来のものが破壊されてしまった。漱石は、それを嘆いたのである。</s>
sample output: 夏目漱石は、明治時代を代表する文豪です。夏目漱石の代表作は「吾輩は猫である」や「坊っちゃん」、「草枕」「三四郎」、それに「虞美人草(ぐびじんそう)」などたくさんあります。¶
コメント powered by CComment