*この記事の内容が少し古くなったので、AIによる自然言語処理に更に興味があるかた向けに記事を追加しました。
*人が書いたのと区別できないほどの文章を自動生成できると言われている日本語GPT2を初心者でも手軽にJupyter Notebookで試せます。
*GitHubにNotebookファイルがあるので参考にしてください。
BERTでの日本語処理方法を、手軽にJupyter Notebookで試せるようにした。
東北大学の研究室で公開している、訓練済み日本語BERTモデルがTransformersで利用できるようになって、かなり使いやすくなった。
使い方を、私を含めたBERET初心者にもわかりやすいようにサンプルを作ってみた。
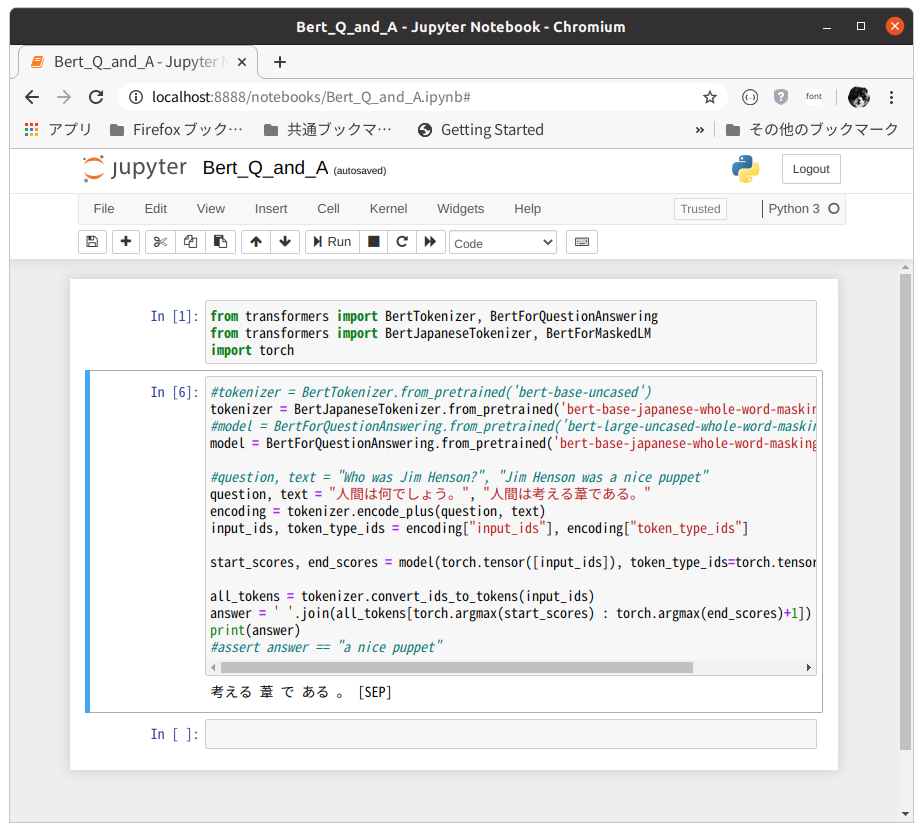
TransformerにあるBertForQuestionAnsweringのサンプルを参考にした。
基本的にはBertTokenizerをBertJapaneseTokenizerで置き換えていけば何とかなりそうだ。
BERTのQA形式のサンプルを使って見たのは、あまり情報が少ないようなのと、BERTの特徴を、あまり難しくしないで、理解しやすいかな、このほうが楽。
英語のサンプルでは
質問:"Who was Jim Henson?"
ヒント:"Jim Henson was a nice puppet"
予想される答え:"a nice puppet"
となっているが
日本語BERTでは少しひねって
質問:"人間は何でしょう。"
ヒント:"人間は考える葦である。"
でどうなるか。
日本語処理の部分はBertJapaneseTokenizerでうまくカプセル化されてるみたいで、とりあえず動かすにはなにもすることがない。
答えが複数ある場合は、羅列してくれる。
とりあえず何回かやってみると
"考える 葦 で ある 。 [SEP]"
と答えてくれた。さすがAI、パスカルの言葉を日本語で理解している。
質問文の中の"何"をうまく[MASK]として使っているようだ。
このレベルまで使いやすくなってくれば、初心者でも関心を持ちやすいチュートリアルになりそうだ。
Bert_Q_and_A
from transformers import BertTokenizer, BertForQuestionAnswering
from transformers import BertJapaneseTokenizer, BertForMaskedLM
import torch
#tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokenizer = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-whole-word-masking')
#model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
model = BertForQuestionAnswering.from_pretrained('bert-base-japanese-whole-word-masking')
#question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
question, text = "人間は何でしょう。", "人間は考える葦である。"
encoding = tokenizer.encode_plus(question, text)
input_ids, token_type_ids = encoding["input_ids"], encoding["token_type_ids"]
start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))
all_tokens = tokenizer.convert_ids_to_tokens(input_ids)
answer = ' '.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1])
print(answer)
#assert answer == "a nice puppet"
コメント powered by CComment