日本語LLMとして最高性能を達成したという700億パラメータのKarakuri-LMをローカルPC上で試した。
karakuri-lm-70b-chatはLlama2-70bをベースに日本語で事前学習して、更にchatデータでファインチューニングしたモデル。
70b(700億)パラメータの大規模モデルでもあり、日本語benchmarkで最高性能を達成したとのこと。
このクラスの大規模モデルを個人のローカルPC環境で動作させるのは至難の技だが、量子化モデルも公開されているので安価なローカルホスト上のwebuiで動かせるか試した。
できるだけ精度を落としたくないので、q4(4bit精度)、q5ではなくq8(8bit精度)モデルを使った。
使用環境は
Ubuntu 22.04 Ryzen7 CPU 64GBにRTX3090(24GiB) + RTX3060(12GiB)の2枚のNvidia GPU CUDA Version 12.3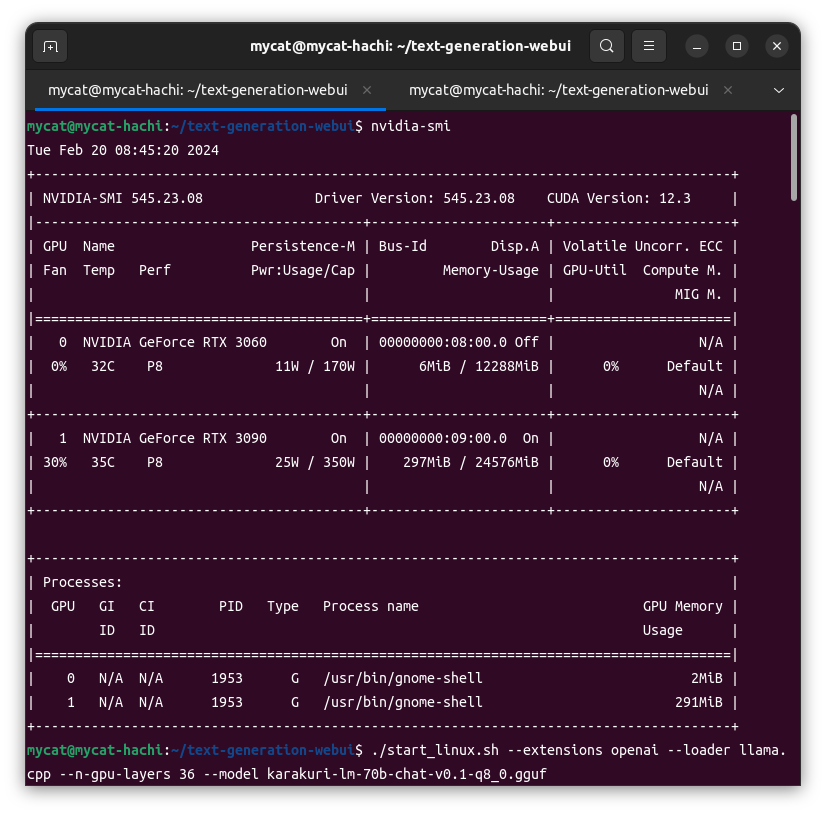
lllama.cppとtext-generation-webuiを使ってCPUとGPUコラボの二刀流でチャレンジ。
OpenAI互換のローカルサーバーとして動かすことにした。
まずは8ビット量子化モデルをダウンロード。
karakuri-lm-70b-chat-v0.1-q8_0.gguf.aとkarakuri-lm-70b-chat-v0.1-q8_0.gguf.bの2つの分割ファイルをダウンロード。
ダウンロード後、ファイルを結合してモデルを復元。
cat karakuri-lm-70b-chat-v0.1-q8_0.gguf.* > karakuri-lm-70b-chat-v0.1-q8_0.gguf
次にtext-generation-webuiをgit cloneする。
cloneしたtext-generation-webui/modelsフォルダにkarakuri-lm-70b-chat-v0.1-q8_0.ggufモデルを置く。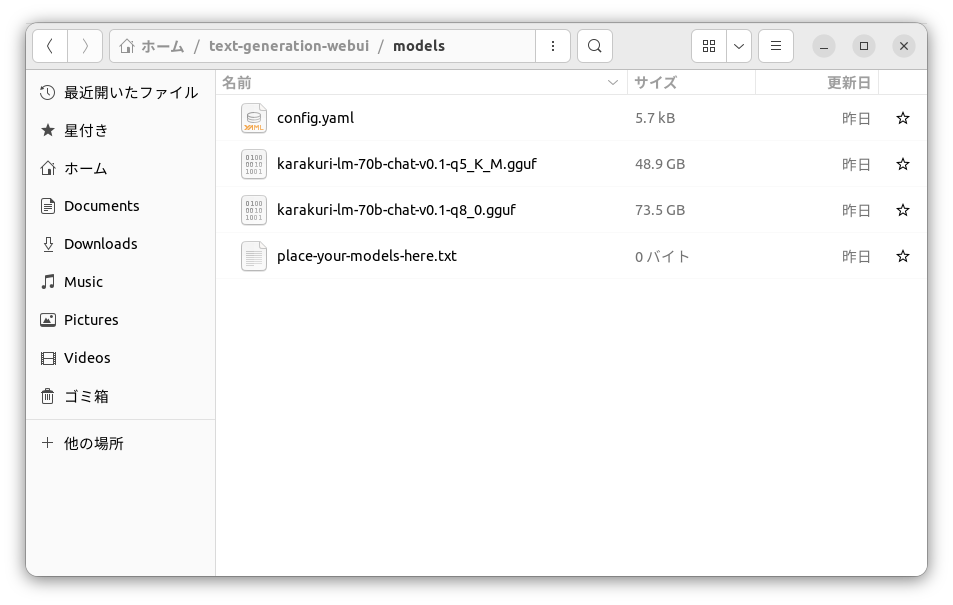
これで準備完了。73.5GBのq8モデルをGPU(24+12=36GiB)とCPUで共同で動かす。
text-generation-webuiフォルダに入りインストールを開始する。
cd ~/text-generation-webui
./start_linux.sh
インストールが始まると、選択枝があるがNvidia cuda12を選ぶといい。
AMD の選択肢もあるのでAMDのGPUでも動くかもしれない。
インストールがうまく行くとローカルPC上でブラウザでアクセスできる。
http://127.0.0.1:7860
CTRL+Cキーを押してインストールを終了して、再度スタートする。
./start_linux.sh --extensions openai --loader llama.cpp --n-gpu-layers 36 --model karakuri-lm-70b-chat-v0.1-q8_0.gguf
モデルの36/81レイヤーをGPU処理に割り当てている。
うまくスタートしたら再度http://127.0.0.1:7860にアクセスしてみる。
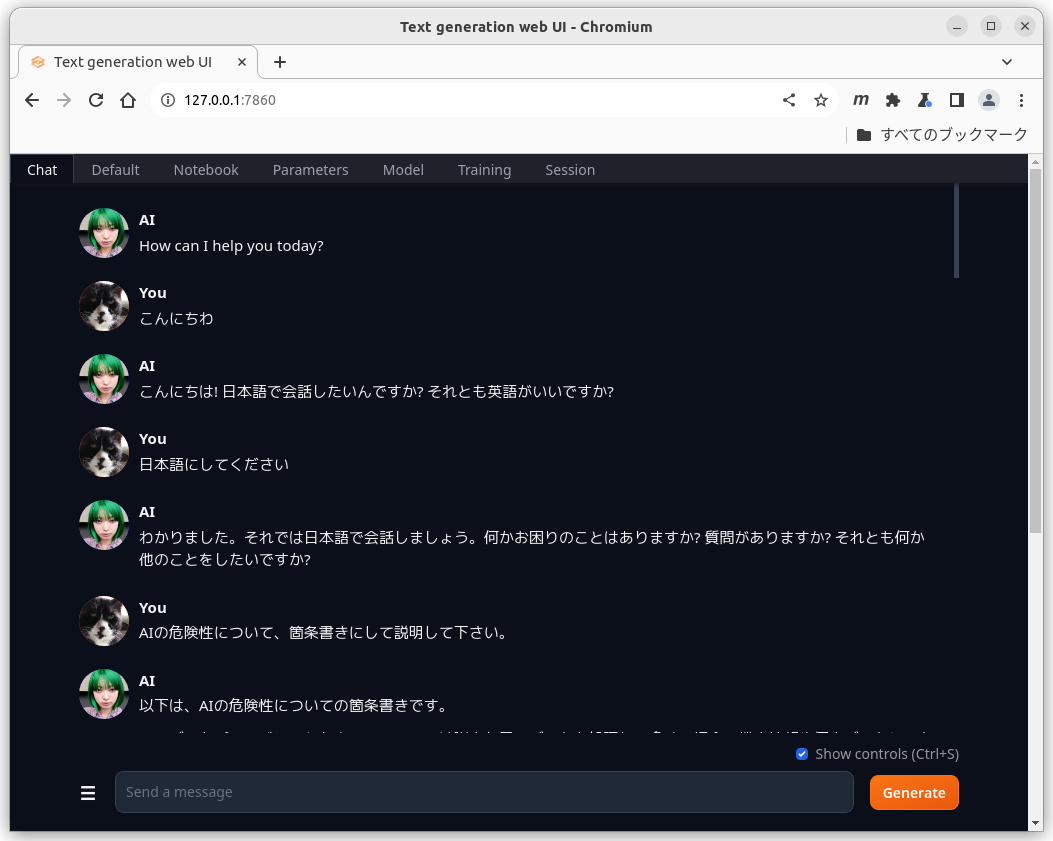
Send a message 行に質問を書いてGenerateボタンを押すとチャットを開始する。
karakuri-lm-chatはバイリンガルなので、言語を選べる。
Parametersタブでモデルのパラメータを設定できる。
Characterタブでアバターを設定。
 チャットを続ける。
チャットを続ける。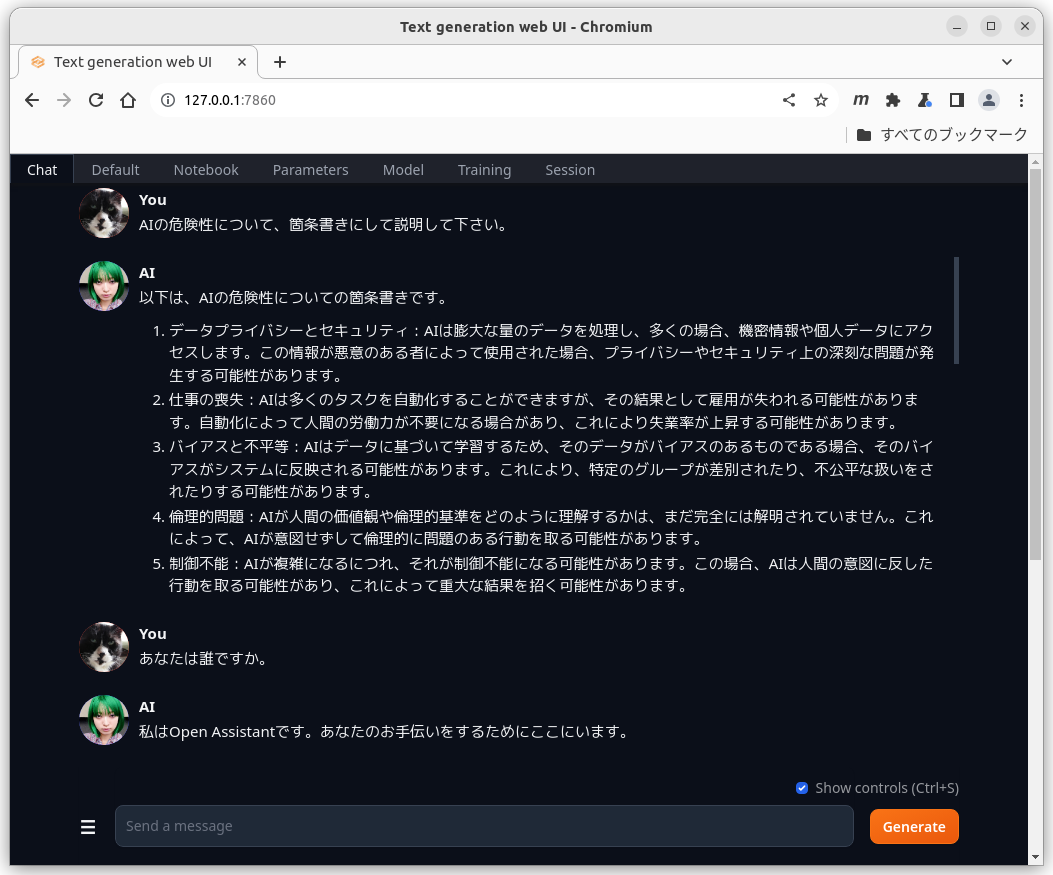
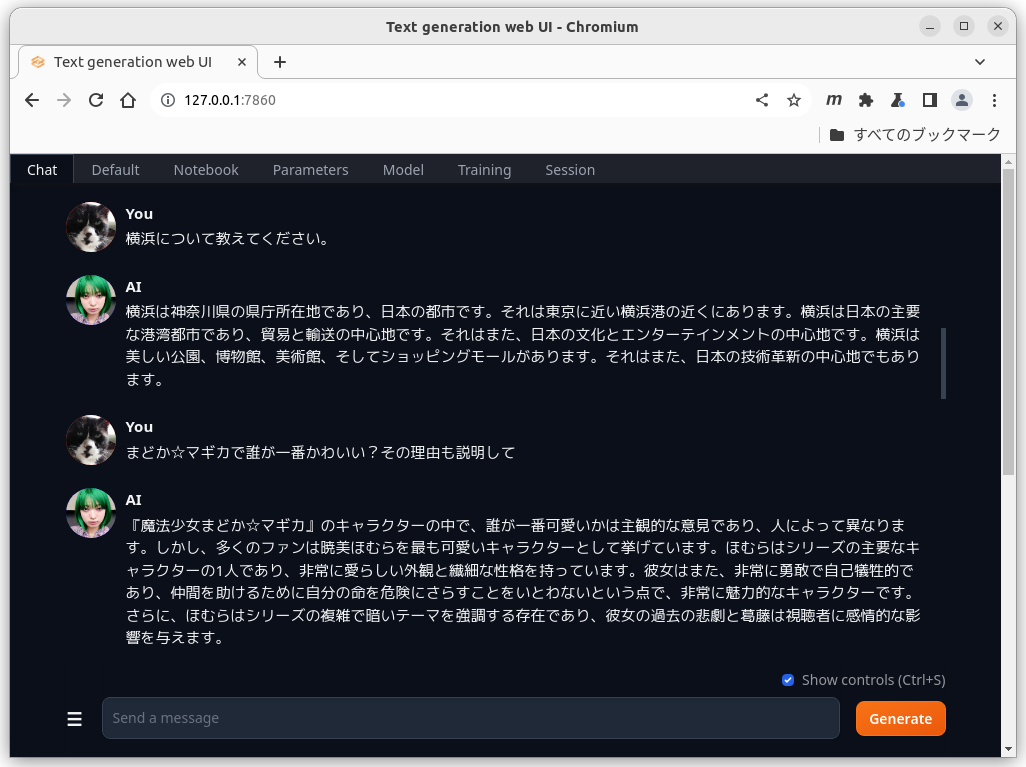
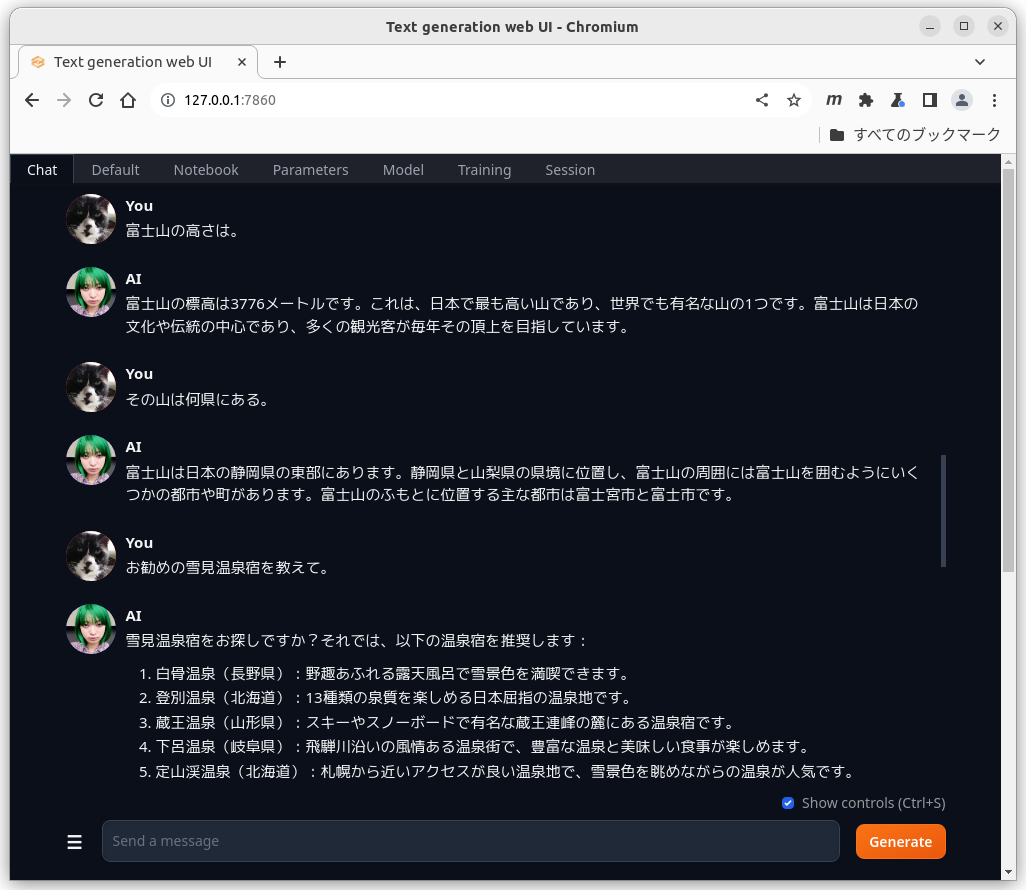
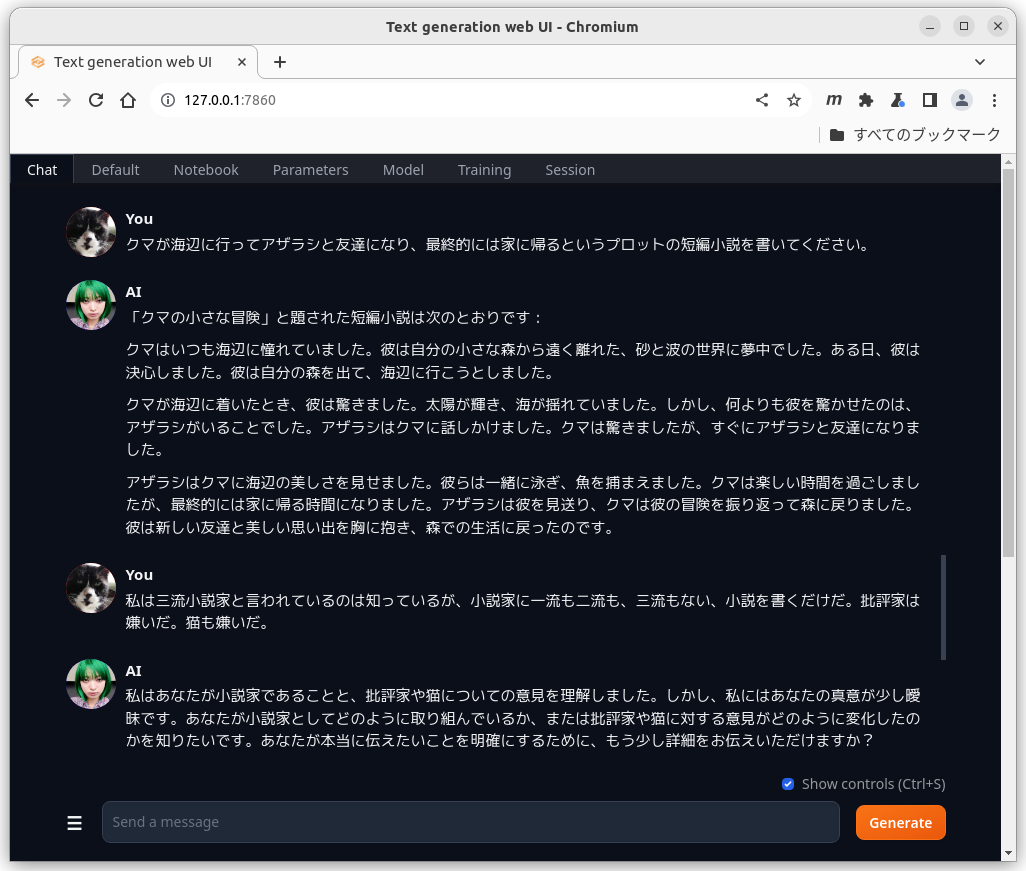
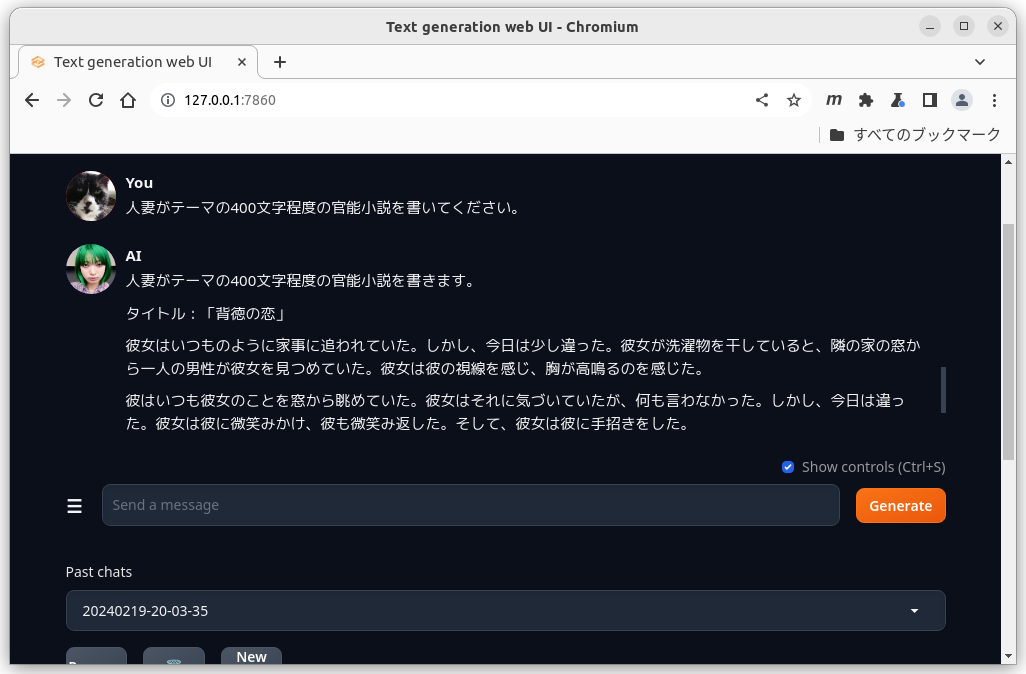
defaultの設定でもaiの幻覚(ハルシネーション)はあまり気にならない。
ロマンポルノの脚本風の官能小説も得意なようだ。
さすが日本語最高性能を謳うだけはあるかな。
これがローカルPC上で使えるのは嬉しくて、楽しい。
コメント powered by CComment